Pandas al diccionario

En Python, se utiliza una estructura de datos llamada diccionario para almacenar información como pares clave-valor. Los objetos del diccionario están optimizados para extraer datos/valores cuando se conoce la clave o claves. Para encontrar valores de manera eficiente utilizando su índice, podemos convertir una serie de pandas o un marco de datos con un índice relevante en un objeto de diccionario con pares clave-valor de índice: valor. El método «to_dict()» se puede utilizar para resolver esta tarea. Esta función es una función integrada que se encuentra en la clase Series del módulo pandas. Un DataFrame se convierte en un diccionario de series de datos similar a pythonlist usando el método pandas.to_dict() dependiendo del valor especificado del parámetro orient.” Usaremos el método to_dict() en pandas. Podemos alinear los pares clave-valor del diccionario devuelto de varias maneras usando la función to_dict(). La sintaxis de la función es la siguiente:
Contenidos
Sintaxis:
pandas.DataFrame_object.to_dict(orientar = «dict», hacia=)
Parámetro:
-
- Orientar: El valor de la cadena («dict», «list», «registros», «index», «series», «split») indica a qué tipo de datos se van a convertir las columnas (series). Por ejemplo, la palabra clave «lista» devolvería un diccionario Python de objetos de lista con las claves «nombre de columna» y «lista» (serie convertida) como salida.
- en: La clase se puede pasar como una instancia o como una clase real. Por ejemplo, una instancia de clase se puede pasar con un dict predeterminado. El valor predeterminado del parámetro es dict.
tipo de retorno:
Diccionario convertido a partir de un marco de datos o serie.
Datos:
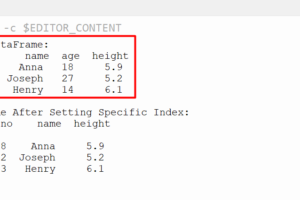
En todos los ejemplos, usamos el siguiente DataFrame llamado «comentarios» que contiene 2 filas y 4 columnas. Aquí están las etiquetas de las columnas: [‘id’,’name’,’status’,’fee’]. import pandas # Crea el dataframe con listenremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Muestra el DataFrame – Remarksprint (Observaciones)
Producción:
id nombre estado fee0 23 sravan pass 10001 21 sravan fail 400
Ejemplo 1: to_dict() sin parámetros
Convertimos el marco de datos de la anotación en un diccionario sin pasar ningún parámetro al método to_dict(). import pandas# Crea el marco de datos con listenremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Convertir a diccionario impreso(observaciones.to_dict())
Producción:
{‘id’: {0:23, 1:21}, ‘name’: {0: ‘sravan’, 1: ‘sravan’}, ‘status’: {0: ‘pass’, 1: ‘fail’} , ‘tarifa’: {0:1000, 1:400}}
explicación
El DataFrame se convierte en un diccionario. Aquí, las columnas en el DataFrame original se han convertido como claves en un diccionario, y cada columna almacena nuevamente dos valores en un formato de diccionario. Las claves para estos valores comienzan en 0.
Ejemplo 2: to_dict() con ‘series’
Convertiremos el marco de datos de la anotación en un diccionario de formato de serie pasando el parámetro «serie» al método to_dict().
formato:
import pandas# Crea el marco de datos con listenremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Convertir a diccionario con una serie de valoresprint(remarks.to_dict(‘series’))
Producción:
{‘id’: 0 231 21Name: id, dtype: int64, ‘name’: 0 sravan1 sravanName: name, dtype: object, ‘status’: 0 pass1 failName: status, dtype: object, ‘fee’: 0 10001 400Name : tarifa, dtype: int64}
explicación
El DataFrame se convierte en un diccionario con el formato «Series». Aquí, las columnas del DataFrame original se han convertido como claves en un diccionario, y cada columna almacena filas junto con el tipo de datos de la columna. El tipo de datos de la columna «id» es int64 y las otras dos columnas son «objeto».
Ejemplo 3: to_dict() con ‘split’
Si desea separar etiquetas de fila, etiquetas de columna y valores en el diccionario convertido, puede usar el parámetro «dividir». Aquí es donde el botón ‘Índice’ almacena una lista de etiquetas de índice. La clave Columnas contiene una lista de nombres de columna y los datos son una lista anidada que almacena cada valor de fila en una lista separada por comas.
formato:

import pandas# Crea el marco de datos con listenremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Convertir a diccionario sin índice ni cabecera print(remarks.to_dict(‘split’))
Producción:
{‘Índice’: [0, 1]’Columnas’: [‘id’, ‘name’, ‘status’, ‘fee’]’Datos’: [[23, ‘sravan’, ‘pass’, 1000], [21, ‘sravan’, ‘fail’, 400]]}
explicación
Podemos ver que se han almacenado dos índices en una lista como el valor de la clave – «Índice». De manera similar, los nombres de las columnas también se almacenan en una lista como un valor para la clave «Columnas», y cada fila se almacena como una lista en una lista anidada para los «datos».
Ejemplo 4: to_dict() con ‘registro’
Si convierte su DataFrame en un diccionario con cada fila como un diccionario en una lista, puede usar el parámetro de registro en el método to_dict(). Aquí, cada fila se coloca en un diccionario, por lo que la clave es el nombre de la columna y el valor es el valor real en el marco de datos de pandas. Todas las filas se han guardado en una lista.
formato:

import pandas# Crea el marco de datos con listenremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Convertir a diccionario por recordprint(remarks.to_dict(‘record’))
Producción:
[{‘id’: 23, ‘name’: ‘sravan’, ‘status’: ‘pass’, ‘fee’: 1000}, {‘id’: 21, ‘name’: ‘sravan’, ‘status’: ‘fail’, ‘fee’: 400}]
Ejemplo 5: to_dict() con ‘índice’
Cada línea se coloca en un diccionario como un valor, con la clave comenzando en 0. Todas las líneas se almacenaron nuevamente en un diccionario.
formato:

import pandas# Crea el marco de datos con listenremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Convertir a diccionario con indexprint (remarks.to_dict(‘index’))
Producción:
[{0: {‘id’: 23, ‘name’: ‘sravan’, ‘status’: ‘pass’, ‘fee’: 1000}, 1: {‘id’: 21, ‘name’: ‘sravan’, ‘status’: ‘fail’, ‘fee’: 400}}
Example 6: OrderedDict()
Let us utilize the ‘into’ parameter that will take OrderedDict, which converts the pandas DataFrame into an Ordered dictionary.
import pandas
from collections import *# Create the dataframe using listsremarks = pandas.DataFrame([[23,’sravan’,’pass’,1000], [21,’sravan’,’fail’,400]],columnas=[‘id’,’name’,’status’,’fee’])# Convertir a OrderedDictprint(remarks.to_dict(into=OrderedDict))
Producción:
OrdenadoDikt([(‘id’, OrderedDict([(0, 23), (1, 21)])), (‘Nombre’, OrderedDict([(0, ‘sravan’), (1, ‘sravan’)])), (‘estado’, OrderedDict([(0, ‘pass’), (1, ‘fail’)])), (‘Tarifa’, OrderedDict([(0, 1000), (1, 400)]))])
Conclusión
Discutimos cómo podemos convertir los objetos dataframe o pandas en un diccionario de Python. Vimos la sintaxis de la función to_dict() para comprender los parámetros de esta función y cómo puede cambiar la salida de la función especificando la función con diferentes parámetros. En los ejemplos de este tutorial, usamos el método to_dict(), una función integrada de Pandas, para cambiar los objetos de Pandas al diccionario de Python.