Grupo MongoDB por múltiples campos
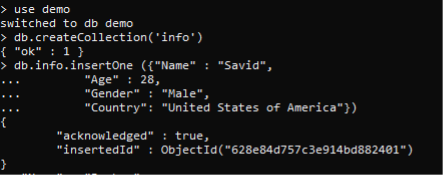
«La base de datos MongoDB juega un papel importante en el almacenamiento y manipulación de datos. Para organizar los datos, creamos grupos para recopilar el mismo tipo de datos en un solo lugar. La agrupación se puede hacer por varios atributos, ya sea de la variable de conteo o de alguna otra característica. Este tutorial explica cómo crear grupos por diferentes campos de documentos. Para implementar el fenómeno de agrupación de campos múltiples, necesitamos tener algunos datos en la base de datos. Primero crearemos una base de datos. Esto se hace especificando el nombre de la base de datos con la palabra clave «uso». Para esta implementación utilizamos una base de datos «demo». Una vez que haya terminado de crear la base de datos, los datos se insertarán en la base de datos. Y para la entrada de datos, que usamos para crear «Colecciones», estos son los contenedores que juegan un papel importante en el almacenamiento de datos ilimitados dentro de ellos. Podemos crear simultáneamente muchas colecciones en una sola base de datos. Aquí creamos una base de datos llamada «info». >> Db.createCollection(‘info’) La respuesta de MongoDB está bien; es la confirmación de la creación de la colección. Los datos de la colección se ingresan línea por línea. Entonces agregaremos datos a la colección. Debido a que estos datos se usan más en ejemplos para crear grupos por diferentes campos, ingresamos muchas filas. A cada fila se le asigna un ID diferente cada vez. >> db.info.insertOne ({«Nombre»: «Savid»,»Edad»: 28,»Sexo»: «Masculino»,»País»: «Estados Unidos de América»})
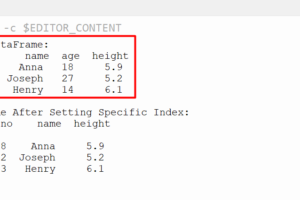
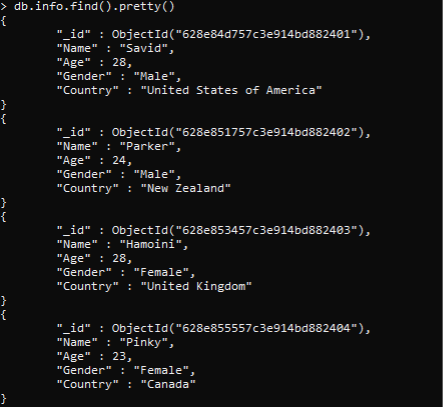
Todos los datos también se insertan. Puede ver todos los datos insertados usando el comando find() >> db.info.find().pretty()
Contenidos
Ejemplo 1: Agrupar por múltiples campos/atributos
Si tenemos una gran cantidad de datos en la base de datos pero queremos ver algunos de ellos, entonces se encontrarán $groups para ese propósito. En este ejemplo, creamos un grupo para mostrar algunos atributos específicos de la colección. El factor de grupo se basa en la operación agregada. Se utiliza una operación agregada para sumar los datos según los campos comunes. El signo de dólar «$» denota la variable. Ahora aplique una consulta a la recopilación de información anterior. Se creará un grupo dependiendo del ID. Y luego solo se seleccionan los documentos de edad y género para su visualización. Se eliminarán todos los datos, incluido el nombre y el país. Esta es una especie de filtro que se usa para limitar la visualización de datos. >> db.info.agregado([ {$group: {_id: {age:»$Age», gender:»$Gender»} } } ])
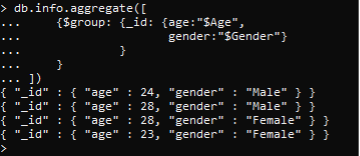
Puede ver que hemos agrupado cada fila por ID restringiendo los datos a dos atributos.
Ejemplo 2: agrupar varios campos aplicando una condición
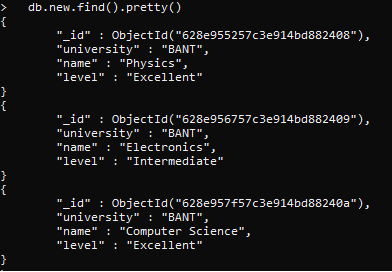
Lo que se entiende es la agrupación de los documentos según una determinada condición. Se crea un grupo para dos atributos y después de la creación del grupo agregamos una variable de recuento para contar las ocurrencias del valor de un documento específico. También agregamos un orden de clasificación. Primero, veamos los documentos en nuestra «nueva» colección. Creamos una colección y le agregamos datos previamente siguiendo los pasos descritos anteriormente. Solo mostraremos todos los elementos de la colección a través de la función find().
La consulta contiene primero la parte del grupo. El grupo se crea en ID; Universidad y Nivel son los dos atributos básicos que queremos que se muestren. La variable que usamos obtiene el valor de la colección y luego lo asigna a la variable de consulta. Todos los valores y condiciones no se escriben directamente en el comando. Después de la creación del grupo, se aplica la condición; contar y calcular la suma según los niveles de cada documento. Después de eso, esta respuesta se ordena en orden descendente. Esto se hace usando las funciones sort(). Esta función solo toma dos parámetros; para valor creciente es 1 y para valor decreciente es -1. >> db.nuevo.agregado([ {$group:{ _id:{ «university»:»$university», «level»:»$level» }, «levelCount»:{«$sum»:1} }}, {«$sort»:{«levelCount»:-1}} ])
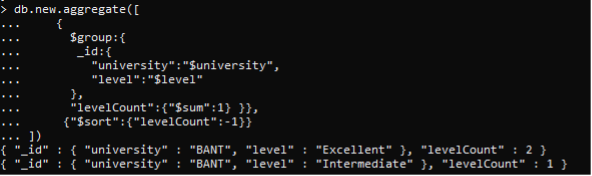
El orden descendente muestra que la cantidad mayor del nivel se muestra primero y luego la menor después del documento de nivel.
Ejemplo 3: Grupo MongoDb BUCKET por múltiples campos
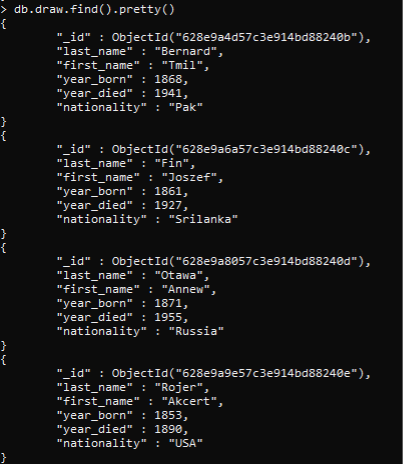
Como sugiere el nombre, los grupos se encuentran por depósito. Esto se hace creando la agregación de depósitos. Con la agregación de cubos, los documentos se clasifican en grupos. Este grupo se comporta como baldes. Cada documento se divide en función de la expresión específica. Para explicar más este concepto, echemos un vistazo a una colección que hemos creado y apliquemos los comandos a ella. Se crea una colección de «dibujar» que almacena información básica sobre un individuo. Hemos mostrado las 4 filas ingresadas previamente en la colección.
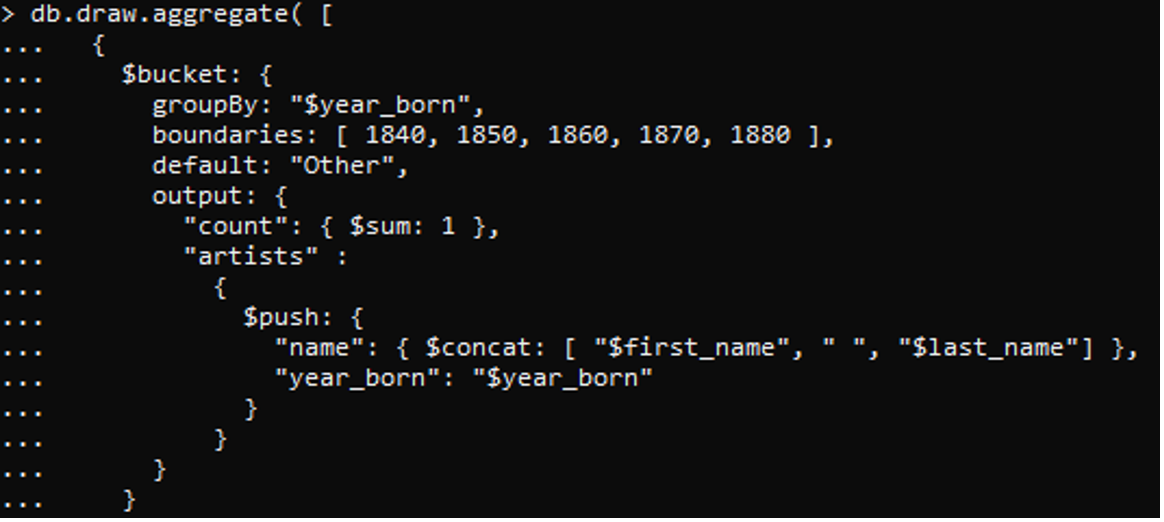
Sobre los datos anteriores, aplicamos un comando para crear un depósito (un grupo) con el año como atributo para agrupar los datos. También hemos creado bordes que indican el año de nacimiento y el año de muerte. Las condiciones aplicadas a este comando incluyen la variable de conteo para contar el número de ocurrencias. También usamos un método de concatenación aquí para combinar nombres y apellidos como cadenas. También se muestra el año de nacimiento. El DNI depende del año.
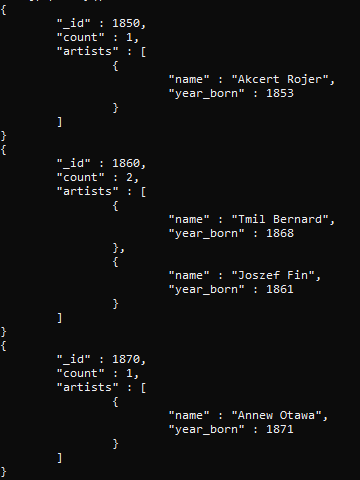
Cuando calculamos esta consulta, el valor resultante muestra que dos filas se agrupan según los límites de edad que creamos.
Conclusión
La característica de MongoDB de agrupar dependiendo de más de un solo campo se explica en este artículo demostrando cómo funciona la operación agregada al crear un grupo. Cualquier función de grupo está incompleta sin la función de agregado. La función de grupo se aplica directamente a los distintos campos para limitar la divulgación de datos completos. La agrupación en varios campos también se realiza aplicando una condición específica. Al final, describimos cómo crear un grupo de depósitos que contenga más elementos como un depósito.