Correlación rodante de Panda
“Las correlaciones móviles se obtienen calculando las correlaciones entre dos series de tiempo usando una ventana móvil. Las correlaciones móviles nos permiten ver si dos series de tiempo correlacionadas difieren con el tiempo”. La correlación móvil en un DataFrame de Pandas se puede encontrar utilizando el método DataFrame_object.rolling().corr(). En esta figura, aprendemos a calcular la correlación móvil en un DataFrame de Pandas usando la técnica básica.
Contenidos
Sintaxis:
En dos DataFrames: DataFrame_object1.rolling(width).corr(DataFrame_object2)
(O)
En dos columnas en un DataFrame: DataFrame_object[‘column1’].rolling(ancho).corr(DataFrame_object[‘column2’]) Al especificar los valores para las columnas, es importante tener en cuenta que la longitud de los valores debe ser la misma para todas las columnas contenidas en el DataFrame. Si ingresamos una longitud de valores diferente, el programa no se ejecutará.
Ejemplo 1: Correlacionar la Columna 1 con la Columna 2
Vamos a crear un marco de datos con 3 columnas y 10 filas y correlacionar la cantidad con la columna de costo durante 2 días. Importar pandas # Crear marco de datos de pandas para calcular la correlación # con 3 columnas. analytics=pandas.DataFrame({‘Producto’:[11,22,33,44,55,66,77,88,99,110]’Multitud’:[200,455,800,900,900,122,400,700,80,500]’costos’:[2400,4500,5090,600,8000,7800,1100,2233,500,1100]})# Correlacionar la cantidad con la columna de costo por 2 días. analítica[‘Correlated’]= análisis[‘quantity’].rolling(2).corr(análisis[‘cost’]) Imprimir (Análisis)
Salida:
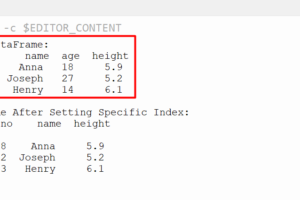
Producto Cantidad COSTO CORRELADO0 11 200 2400 NAN1 22 4500 1.02 33 44 900 600 -1.04 55 900 8000 NAN5 66 122 77 400 1100 2233 1.08 90 500 1.0 1.0 La correlación para 0 Días a 40, 20 etc. la columna Correlacionada.
Ejemplo 2: visualización
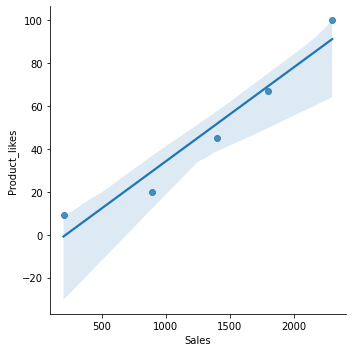
Vamos a crear un DataFrame con 3 columnas y 5 filas y correlacionar Ventas con Product_likes. Utilice Seaborn para trazar la correlación y obtener el coeficiente de correlación de Pearson. import pandas import seaborn from scipy import stats# Crear marco de datos de pandas para calcular la correlación# con 3 columnas.analytics=pandas.DataFrame({‘Nombre del producto’:[‘tv’,’steel’,’plastic’,’leather’,’others’]’Producto_me gusta’:[100,20,45,67,9]’Venta’:[2300,890,1400,1800,200]})print(analytics)print()# Ver Coeficiente de correlaciónprint(stats.pearsonr(analytics[‘Sales’]analítica[‘Product_likes’]))print()# Ahora mire la correlación Ventas vs Product_likesseaborn.lmplot(x=»Sales», y=»Product_likes», data=analytics)
Salida:
Nombre del producto Product_likes Ventas 0 tv 100 2300 1 acero 20 890 2 plástico 45 1400 3 cuero 67 1800 4 otro 9 200(0.9704208315867275, 0.006079620327457793)
Ahora puede ver la correlación entre Ventas y Product_likes. Ahora obtengamos la correlación actual para estas dos columnas durante 3 días.
Código para el ejemplo 2:
# Correlacione las ventas con la columna Product_likes durante 5 días. análisis[‘Correlated’]= análisis[‘Sales’].rolling(3).corr(análisis[‘Product_likes’]) Imprimir (Análisis)
Salida:
Product Name Product_likes Sales Correlated0 TV 100 2300 NaN1 Steel 20 890 NaN2 Plastic 45 1400 0.9984963 Leather 67 1800 0.9994614 Other 9 200 0.989855 Puede ver que estas dos columnas están altamente correlacionadas.
Ejemplo 3: diferentes marcos de datos
Vamos a crear 2 DataFrames con 1 columna cada uno y correlacionarlos. import pandas import seaborn from scipy import statsanalytics1=pandas.DataFrame({ ‘Sales’:[2300,890,1400,1800,200,2000,340,56,78,0]})analytics2=pandas.DataFrame({‘Product_likes’:[100,20,45,67,9,90,8,1,3,0]})# Ver el coeficiente de correlación para los dos DataFramesprint(stats.pearsonr(analytics1) anteriores[‘Sales’]Analítica2[‘Product_likes’]))# Correlacionar ventas con valores similares a productos DataFrameprint(analytics1[‘Sales’].rolling(5).corr(análisis2[‘Product_likes’]))
Salida:
Puede ver que estas dos columnas están fuertemente correlacionadas
Diploma
Esta discusión gira en torno a calcular la ventana móvil y luego encontrar la correlación de un Pandas DataFrame. Para poner en práctica estos dos conceptos, Pandas proporciona un práctico método DataFrame.rolling().corr(). Para ayudar al alumno a comprender mejor el proceso, proporcionamos tres ejemplos de la vida real junto con la visualización y el módulo Searborn. Cada ejemplo se elabora con una explicación detallada de los pasos. Puede aplicarlo a diferentes columnas en un solo DataFrame o usar las mismas columnas de diferentes DataFrames; todo depende de sus requisitos.