Principios y práctica en la capa de repositorio | de Chen Zhang | diciembre 2022
Contenidos
Mapeo de datos, caché, concurrencia y flujo de datos
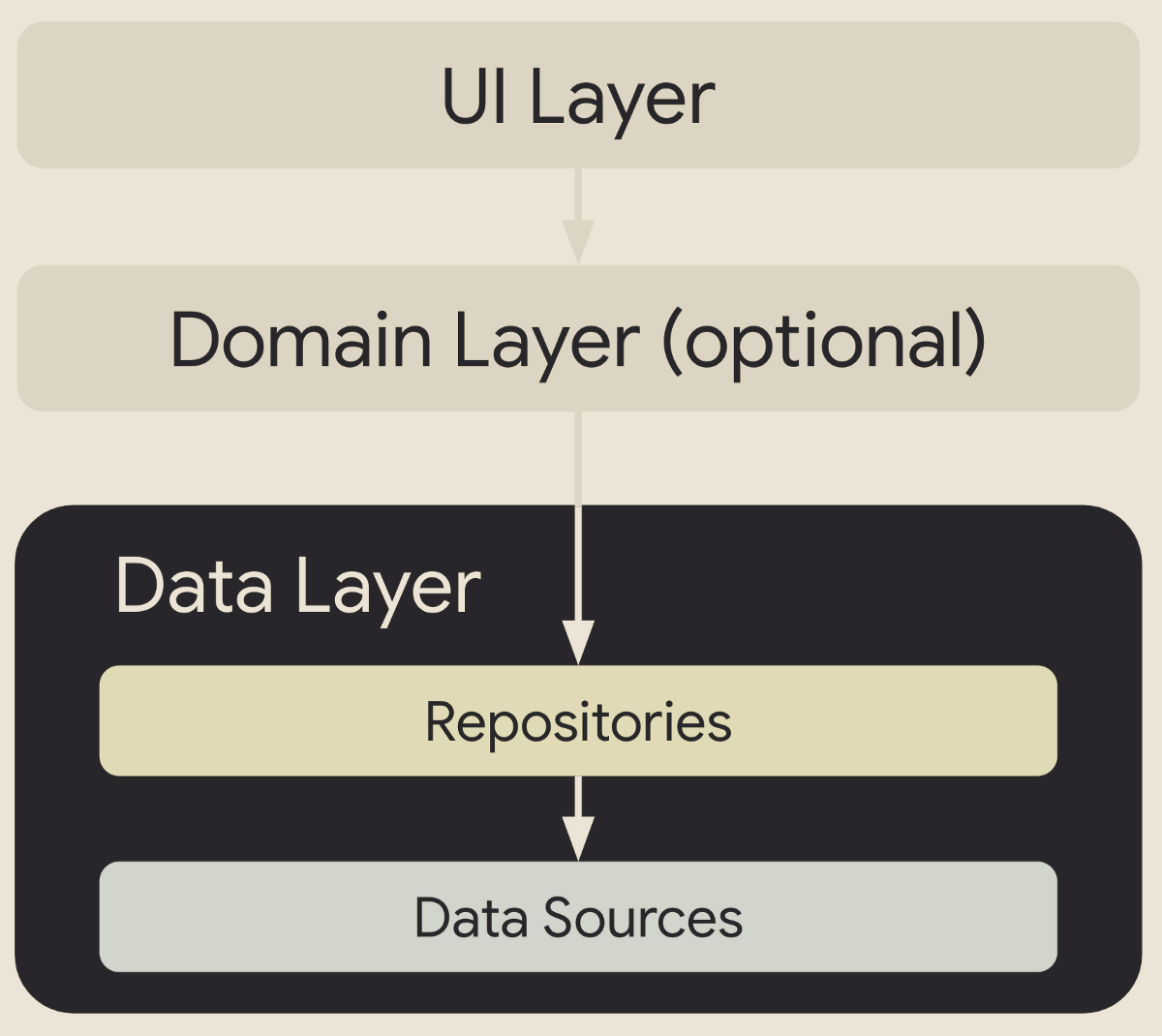
Todas las aplicaciones modernas de Android adoptan algunas variaciones arquitectónicas, siendo MVVM o MVI las más comunes. Independientemente de la arquitectura, todos definen una capa utilizando el patrón de repositorio. Recientemente investigué la refactorización en la capa del repositorio y encontré un par de errores. Empecé esto como mi propio memorándum. Pero reconoció que algunas sugerencias y códigos pueden ser útiles para que otros eviten trampas. ¿Por qué necesitamos una arquitectura de aplicaciones? Porque nos ayuda a gestionar la complejidad dividiéndola en módulos con responsabilidades distintas e interrelacionadas. La capa de repositorio no es una excepción. Estas son las pocas responsabilidades distintas en este nivel:
mapeo de datos
Un repositorio media entre el dominio y la fuente de datos. Asigna datos a modelos de dominio para que la capa de dominio solo tenga que lidiar con los modelos de dominio para la lógica comercial. Gracias a los repositorios, todos los modelos de datos de red deberían estar ocultos de la capa de dominio. Tome GraphQL como ejemplo, los datos de la red son generados por el esquema GQL definido por los servicios de back-end. No queremos que estos modelos de red definidos externamente se filtren a ninguna capa más allá de los repositorios. Por lo tanto, los repositorios se ocupan del mapeo de datos y ocultan el mecanismo de red subyacente de la capa de dominio.
cache
Si se utiliza un caché de datos, los repositorios deben encapsular el mecanismo de almacenamiento en caché subyacente, p. B. Cachés en memoria o en disco.
paralelismo
Los cachés deben admitir consultas simultáneas del dominio. Las aplicaciones modernas de Android usan corrutinas que logran la asincronía al pausar y reanudar el trabajo en las continuaciones implícitas. Las aplicaciones de Android más antiguas pueden usar procesamiento paralelo de subprocesos múltiples. Pero en cualquier caso, la capa de repositorio en caché debe ser segura para la concurrencia.
único fuente de verdad
Dado que la capa de repositorio asume la responsabilidad y encapsula el mapeo de datos, el almacenamiento en caché y la seguridad de la concurrencia, debe convertirse en la única fuente de verdad para los modelos de dominio apropiados en toda la aplicación. Busque otras fuentes en la aplicación para los mismos modelos o submodelos de dominio. Probablemente sean las fuentes equivocadas y deben ser rechazadas. Esto es especialmente importante cuando se trata de concurrencia y las fuentes inseguras podrían causar condiciones de carrera. Un caso de uso común para el patrón Repositorio es admitir la memoria caché. Para garantizar la seguridad de la concurrencia, queremos asegurarnos de que los accesos (lecturas y escrituras) a la memoria caché estén sincronizados. Aquí hay un fragmento para ilustrar un caché en memoria en un entorno concurrente con algunas leyendas.
- Mutex es un modismo en las rutinas de Kotlin para bloqueos mutuamente excluyentes.
- Si el caché está disponible (suponiendo que haya fondos disponibles que no sean cero), devolvemos el caché inmediatamente
- Si el caché no está disponible, use mutex para permitir que solo se ejecute la primera corrutina dentro de withLock{} lambda. Todas las corrutinas simultáneas esperan a que se acceda al bloqueo mutex.
- La primera rutina realizaría la operación de red en el subproceso de E/S, asignaría la red al modelo de dominio, la almacenaría en caché y devolvería
- Después de que la primera corrutina haya terminado de ejecutarse en la lambda withLock{} , la siguiente corrutina que antes estaba esperando el bloqueo ahora puede ingresar con withLock{} . Siempre debe verificar si el caché ya está disponible como resultado de la primera rutina. Eso es importante, dado que estas corrutinas en espera ya pasaron la primera verificación de caché y están esperando la entrada de bloqueo mutex. Si escriben withLock{} y no vuelven a comprobar la memoria caché, volverán a ejecutar la consulta de red, lo que provocará ineficiencia y posibles errores. Por lo tanto, queremos verificar la cuenta en caché por segunda vez. Tiene un propósito diferente en un entorno de concurrencia.
- Tenga en cuenta que ambas comprobaciones de caché no requieren cambiar al despachador de E/S si la caché está disponible. Devolvemos el caché inmediatamente en el mismo hilo.
Las llamadas anteriores se implementan para lograr seguridad y eficiencia. Espero que tengan sentido. Los principios de implementación deben ser aplicables a otros modelos de almacenamiento en caché, concurrencia o red. También me gustaría mencionar algunas palabras sobre StateFlow de Kotlin, ya que está ganando popularidad en estos días gracias a un caso de uso común en Android para implementar el patrón observable del titular del estado como reemplazo del tradicional Android LiveData.StateFlow no solo puede ser utilizado en ViewModel para exponer observables a la capa de la interfaz de usuario, también se puede aplicar a la capa del repositorio. Por ejemplo, si un usuario ha cerrado sesión, queremos monitorear el estado de inicio de sesión y borrar todos los cachés para ese usuario. En este caso, podemos exponer un flujo de estado de inicio de sesión para que StateFlow emita un nuevo estado cuando un usuario inicia o cierra sesión. Aquí hay un fragmento muy simplificado: hay algunos atributos de StateFlow que debemos conocer para aplicarlo y usarlo correctamente en la situación correcta:
- StateFlow es como otras API de flujo, el lado del generador (generador de flujo) no está expuesto y no requiere un área de rutina. Pero el lado del suscriptor (consumidor) con las operaciones de la terminal (como recolectar{}) debe estar en un ámbito de rutina.
- Varios consumidores pueden suscribirse a StateFlow. Entonces, StateFlow está «caliente», lo que significa que el lado del fabricante está emitiendo artículos de manera proactiva. Esto difiere de muchas otras API de flujo, que son «frías», lo que significa que son perezosas y no comenzarán a generar resultados hasta que el consumidor se suscriba a ellas con operaciones de terminal.
- StateFlow siempre representa el último elemento. Es decir, si un consumidor se suscribe a él, primero se recibirá el artículo más nuevo y luego las emisiones posteriores.
Espero que estos consejos y sugerencias a nivel de repositorio puedan ayudar a otros a resolver problemas comunes y evitar trampas.
 Oferta Movistar: Las mejores tarifas
Oferta Movistar: Las mejores tarifas Clubhouse y su versión Android
Clubhouse y su versión Android Controla el consumo de CPU y GPU cuando juegas en Windows
Controla el consumo de CPU y GPU cuando juegas en Windows Pepephone datos ilimitados
Pepephone datos ilimitados Tarifas Prepago de Lebara
Tarifas Prepago de Lebara Google Reader para Android
Google Reader para Android Videos en iOS y Android sin YouTube
Videos en iOS y Android sin YouTube Android imita a Apple en la búsqueda de móviles
Android imita a Apple en la búsqueda de móviles Cómo configurar Clubhouse en Android
Cómo configurar Clubhouse en Android 12 Mejores navegadores GPS en Android
12 Mejores navegadores GPS en Android




