Meta lanza un nuevo conjunto de datos para ayudar a los investigadores de IA a maximizar la inclusión y la diversidad en sus proyectos

Meta tiene como objetivo ayudar a los investigadores de IA a hacer que sus herramientas y procesos sean más universalmente inclusivos mediante la publicación de un nuevo conjunto masivo de datos de clips de video cara a cara que abarcan una amplia gama de personas diferentes que ayudarán a los desarrolladores a medir qué tan bien funcionan sus modelos para diferentes grupos de población.
Hoy ofrecemos Casual Conversations v2 de código abierto: un conjunto de datos basado en consenso de monólogos grabados que incluye diez categorías personalizadas y comentadas que permiten a los investigadores evaluar la imparcialidad y solidez de los modelos de IA. Más detalles sobre este nuevo conjunto de datos ⬇️— Meta KI (@MetaAI) 9 de marzo de 2023
Como puede ver en este ejemplo, la base de datos Casual Conversations v2 de Meta contiene 26 467 monólogos en video grabados en siete países y tiene 5567 participantes pagados, con datos de atributos demográficos, visuales y de voz para medir la efectividad sistemática. Según Meta: “El conjunto de datos basado en el consentimiento se informó y se formó a través de una extensa revisión de la literatura sobre categorías demográficas relevantes y se creó en consulta con expertos internos en áreas como los derechos civiles. Este conjunto de datos proporciona una lista detallada de 11 categorías autoproporcionadas y anotadas para medir aún más la equidad y la solidez algorítmica en estos sistemas de IA. Hasta donde sabemos, es el primer conjunto de datos de código abierto de videos recopilados de varios países que utilizan información demográfica muy precisa y detallada para probar la imparcialidad y la solidez de los modelos de IA”. Meta tiene muy claro que estos datos se obtuvieron con el permiso directo de los participantes y no se obtuvieron de forma encubierta. Por lo tanto, no toma su información de Facebook ni proporciona imágenes de IG: el contenido incluido en este conjunto de datos se diseñó para maximizar la inclusión al proporcionar a los investigadores de IA más muestras de personas de diversos orígenes para usar en sus modelos. Curiosamente, la mayoría de los participantes provienen de India y Brasil, dos economías digitales emergentes que desempeñarán un papel importante en la próxima fase de desarrollo tecnológico.
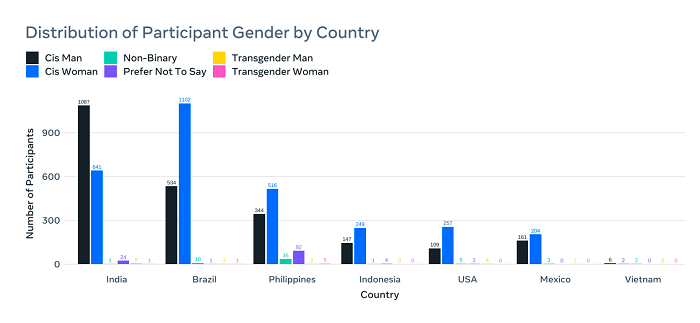
El nuevo conjunto de datos ayudará a los desarrolladores de IA a abordar las preocupaciones sobre las barreras del idioma y la diversidad física que han sido problemáticas en algunos contextos de IA. Por ejemplo, algunas herramientas de superposición digital no reconocieron ciertos atributos de los usuarios debido a limitaciones en sus modelos de entrenamiento, mientras que algunas se consideraron totalmente racistas, al menos en parte debido a limitaciones similares. Este es un enfoque clave de la documentación de Meta sobre el nuevo conjunto de datos: «Con las crecientes preocupaciones sobre el rendimiento de los sistemas de IA en diferentes escalas de tonos de piel, decidimos usar dos escalas diferentes para la anotación del tono de piel. La primera es la escala de Fitzpatrick de seis tonos, que es el esquema de clasificación numérica más utilizado para los tonos de piel debido a su simplicidad y uso generalizado. La segunda es la escala de tonos de piel de 10 tonos, presentada por Google y utilizada en sus servicios de búsqueda y fotografía. La inclusión de ambas escalas en Casual Conversations v2 proporciona una comparación más clara con el trabajo anterior que usa la escala Fitzpatrick, al tiempo que permite la medición basada en la escala Monk más completa». Esta es una consideración importante, especialmente dado que las herramientas de IA generativa continúan ganando importancia y ver un uso creciente en muchas otras aplicaciones y plataformas. Para maximizar la inclusión, estas herramientas deben capacitarse en conjuntos de datos extendidos, lo que garantiza que todos se tengan en cuenta en dicha implementación y que cualquier error u omisión se detecte antes del lanzamiento. El conjunto de datos de conversaciones casuales de Meta ayudará con esto y podría ser un conjunto de capacitación extremadamente valioso para proyectos futuros. Puede leer más sobre la base de datos de Meta’s Casual Conversations v2 aquí.
 Megan Ewoldsen sobre la creación de un guardarropa elegante con un presupuesto
Megan Ewoldsen sobre la creación de un guardarropa elegante con un presupuesto Las nuevas tarifas de acceso a la API de Twitter podrían excluir a muchas aplicaciones e investigadores de sus proyectos
Las nuevas tarifas de acceso a la API de Twitter podrían excluir a muchas aplicaciones e investigadores de sus proyectos Marketing de bufetes de abogados: por qué su bufete de abogados debe volverse social
Marketing de bufetes de abogados: por qué su bufete de abogados debe volverse social Twitter ofrece nuevos conocimientos sobre cómo los especialistas en marketing pueden alinearse con el compromiso de March Madness
Twitter ofrece nuevos conocimientos sobre cómo los especialistas en marketing pueden alinearse con el compromiso de March Madness Recuperación de Relaciones Comerciales – Explorador de Redes Sociales
Recuperación de Relaciones Comerciales – Explorador de Redes Sociales 5 consejos rápidos y fáciles para impulsar su estrategia de redes sociales en 2023 [Infographic]
5 consejos rápidos y fáciles para impulsar su estrategia de redes sociales en 2023 [Infographic] Lo que nos enseñó a pasar 12 mil millones de horas al día en las redes sociales
Lo que nos enseñó a pasar 12 mil millones de horas al día en las redes sociales Meta maneja proyectos NFT para enfocarse en otros elementos
Meta maneja proyectos NFT para enfocarse en otros elementos Google quiere agregar IA generativa a Gmail, Docs, Slides y más
Google quiere agregar IA generativa a Gmail, Docs, Slides y más TikTok considera la venta para disipar las preocupaciones sobre los conflictos de propiedad
TikTok considera la venta para disipar las preocupaciones sobre los conflictos de propiedad


