Ahora puede ejecutar un modelo de IA de nivel GPT 3 en su computadora portátil, teléfono y Raspberry Pi


Ars Technica AI Land se mueve a la velocidad del rayo. El viernes, un desarrollador de software llamado Georgi Gerganov creó una herramienta llamada «llama.cpp» que puede ejecutar el nuevo modelo de lenguaje de IA de clase GPT-3 grande de Meta, LLaMA, localmente en una computadora portátil Mac. Poco después, la gente descubrió cómo hacer que LLaMA también se ejecutara en Windows. entonces alguien mostró que funciona en un teléfono Pixel 6, y luego vino una frambuesa pi (aunque muy lentamente). Si esto continúa, es posible que estemos ante un competidor de ChatGPT de bolsillo antes de que nos demos cuenta. Pero retrocedamos un minuto porque aún no hemos llegado allí. (Al menos no hoy, literalmente hoy, 13 de marzo de 2023). Pero lo que llegará la próxima semana, nadie lo sabe. Desde el lanzamiento de ChatGPT, algunas personas se han sentido frustradas por las limitaciones integradas del modelo de IA, que le impiden discutir temas que OpenAI considera sensibles. Así comenzó, en algunos círculos, el sueño de un modelo de lenguaje grande (LLM) de código abierto que cualquiera pudiera ejecutar localmente sin censura y sin pagar tarifas de API a OpenAI. Existen soluciones de código abierto (como GPT-J), pero requieren mucha RAM de GPU y espacio en disco. Otras alternativas de código abierto no han podido ofrecer un rendimiento de nivel GPT-3 en hardware de nivel de consumidor fácilmente disponible. Ingrese a LLaMA, un LLM disponible en tamaños de parámetros de 7B a 65B (eso es «B» como en «mil millones de parámetros», que son números de punto flotante almacenados en matrices que representan lo que el modelo «sabe»). LLaMA hizo una afirmación embriagadora: que sus modelos más pequeños podrían igualar el GPT-3 de OpenAI, el modelo fundamental que impulsa ChatGPT, en la calidad y velocidad de su salida. Solo había un problema: Meta lanzó el código LLaMA como fuente abierta, pero retuvo los «pesos» (el «conocimiento» entrenado almacenado en una red neuronal) solo para investigadores calificados. Publicidad
Vuela a la velocidad de LLaMA
Las restricciones de Meta sobre LLaMA no duraron mucho ya que el 2 de marzo alguien filtró los pesos de LLaMA en BitTorrent. Desde entonces, el desarrollo en torno a LLaMA se ha disparado. El investigador independiente de inteligencia artificial Simon Willison comparó esta situación con el lanzamiento de Stable Diffusion, un modelo de síntesis de imágenes de código abierto lanzado en agosto pasado. Esto es lo que escribió en una publicación en su blog:
Me parece que ese momento de difusión estable en agosto inició toda una nueva ola de interés en la IA generativa, que luego se puso en marcha con el lanzamiento de ChatGPT a fines de noviembre. Ese momento de difusión estable está ocurriendo nuevamente en este momento, para modelos de lenguaje grandes: la tecnología detrás de ChatGPT. ¡Esta mañana ejecuté un modelo de lenguaje de clase GPT-3 en mi propia computadora portátil por primera vez! Las cosas de la IA eran raras. Se vuelve aún más extraño.
Por lo general, ejecutar GPT-3 requiere múltiples GPU A100 de clase de centro de datos (incluso los pesos para GPT-3 no son públicos), pero LLaMA llamó la atención por poder ejecutarse en una sola GPU de consumo robusta. Y ahora, con optimizaciones que reducen el tamaño del modelo usando una técnica llamada cuantización, LLaMA puede ejecutarse en una GPU M1 Mac o Nvidia más pequeña. Las cosas se mueven tan rápido que a veces es difícil mantenerse al día con los últimos desarrollos. (Con respecto a la tasa de progresión de la IA, otro reportero de la IA le dijo a Ars: «Es como esos videos de perros en los que les arrojas una caja de pelotas de tenis. [They] No sé dónde cazar primero y me pierdo en la confusión»). Por ejemplo, aquí hay una lista de eventos notables relacionados con LLaMA, basada en una línea de tiempo establecida por Willison en un comentario de Hacker News:
- 24 de febrero de 2023: Meta AI anuncia LLaMA.
- 2 de marzo de 2023: Alguien publica los modelos de LLaMA a través de BitTorrent.
- 10 de marzo de 2023: Georgi Gerganov crea llama.cpp que se ejecuta en una Mac M1.
- 11 de marzo de 2023: Artem Andreenko corre LLaMA 7B (lento) en una Raspberry Pi 44 GB de RAM, 10 seg/token.
- 12 de marzo de 2023: LLaMA 7B se ejecuta en NPX, una herramienta de ejecución de node.js.
- 13 de marzo de 2023: Alguien hace funcionar llama.cpp en un teléfono Pixel 6también muy lento.
- 13 de marzo de 2023: Stanford lanza Alpaca 7B, una versión ajustada por instrucciones de LLaMA 7B que «se comporta de manera similar al texto-davinci-003 de OpenAI», pero se ejecuta en un hardware mucho menos potente.
Después de obtener nosotros mismos los pesos de LLaMA, seguimos las instrucciones de Willison y conseguimos que la versión paramétrica 7B funcionara en un Macbook Air M1 y funciona a una velocidad razonable. Lo invoca como un script en la línea de comandos con un símbolo del sistema, y LLaMA hará todo lo posible para completarlo de manera sensata.
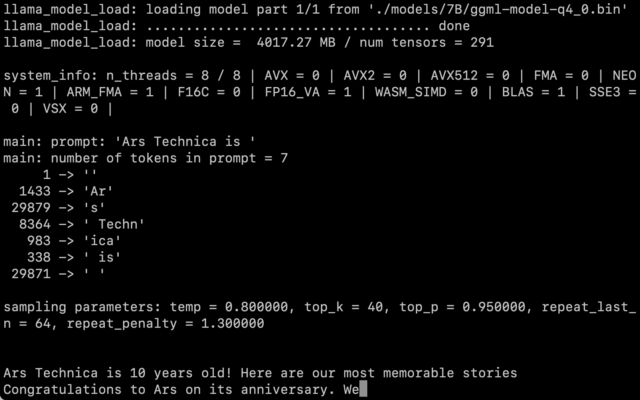 Ampliar / Una captura de pantalla del LLaMA 7B en acción en un MacBook Air con llama.cpp.Benj Edwards / Ars Technica La pregunta sigue siendo cuánto afecta la cuantificación a la calidad de la salida. En nuestras pruebas, LLaMA 7B, reducido a cuantización de 4 bits, fue muy impresionante para ejecutarse en una MacBook Air, pero aún no al nivel que cabría esperar de ChatGPT. Es muy posible que mejores técnicas de incitación conduzcan a mejores resultados. Las optimizaciones y los ajustes también son rápidos cuando todo el mundo tiene el código y los pesos a mano, aunque LLaMA todavía tiene algunos términos de servicio bastante restrictivos. El lanzamiento de Alpaca de Stanford de hoy demuestra que el ajuste fino (entrenamiento adicional con un objetivo específico en mente) puede mejorar el rendimiento, y aún es pronto después del lanzamiento de LLaMA. Al momento de escribir este artículo, ejecutar LLaMA en una Mac sigue siendo un ejercicio bastante técnico. Debe tener Python y Xcode instalados y estar familiarizado con el trabajo en la línea de comandos. Willison tiene buenas instrucciones paso a paso para cualquiera que quiera probar. Pero eso podría cambiar pronto a medida que los desarrolladores continúen programando. En cuanto al impacto de esta tecnología en la naturaleza, nadie lo sabe todavía. Si bien algunos se preocupan por el impacto de la IA como herramienta para enviar spam e información errónea, Willison dice: «No pasará desapercibida, por lo que creo que nuestra prioridad debería ser encontrar las formas más constructivas en las que se puede usar». , nuestra única garantía es que las cosas cambiarán rápidamente.
Ampliar / Una captura de pantalla del LLaMA 7B en acción en un MacBook Air con llama.cpp.Benj Edwards / Ars Technica La pregunta sigue siendo cuánto afecta la cuantificación a la calidad de la salida. En nuestras pruebas, LLaMA 7B, reducido a cuantización de 4 bits, fue muy impresionante para ejecutarse en una MacBook Air, pero aún no al nivel que cabría esperar de ChatGPT. Es muy posible que mejores técnicas de incitación conduzcan a mejores resultados. Las optimizaciones y los ajustes también son rápidos cuando todo el mundo tiene el código y los pesos a mano, aunque LLaMA todavía tiene algunos términos de servicio bastante restrictivos. El lanzamiento de Alpaca de Stanford de hoy demuestra que el ajuste fino (entrenamiento adicional con un objetivo específico en mente) puede mejorar el rendimiento, y aún es pronto después del lanzamiento de LLaMA. Al momento de escribir este artículo, ejecutar LLaMA en una Mac sigue siendo un ejercicio bastante técnico. Debe tener Python y Xcode instalados y estar familiarizado con el trabajo en la línea de comandos. Willison tiene buenas instrucciones paso a paso para cualquiera que quiera probar. Pero eso podría cambiar pronto a medida que los desarrolladores continúen programando. En cuanto al impacto de esta tecnología en la naturaleza, nadie lo sabe todavía. Si bien algunos se preocupan por el impacto de la IA como herramienta para enviar spam e información errónea, Willison dice: «No pasará desapercibida, por lo que creo que nuestra prioridad debería ser encontrar las formas más constructivas en las que se puede usar». , nuestra única garantía es que las cosas cambiarán rápidamente.





