
Eliminar NA en R
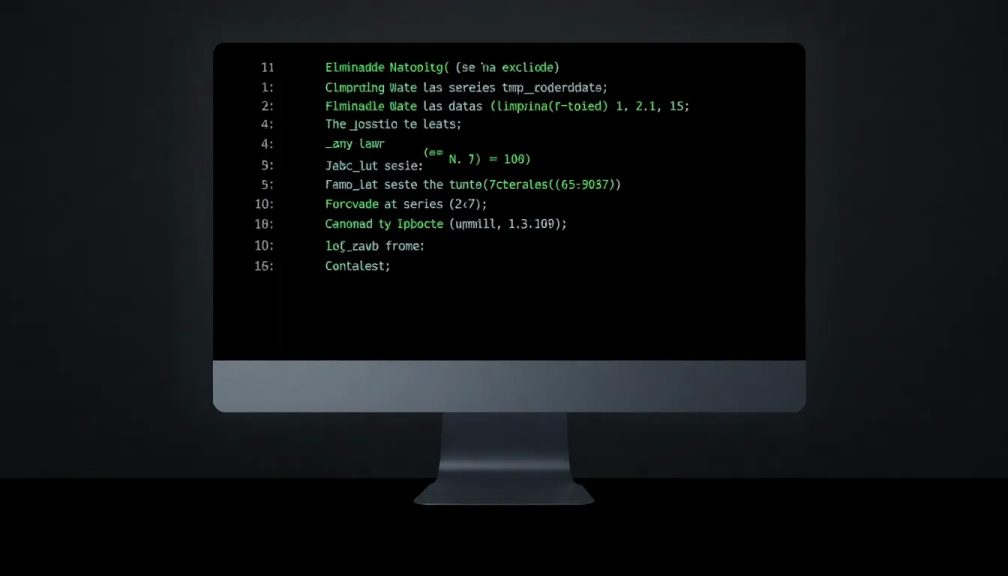
El manejo de datos en R es una habilidad esencial para cualquier analista o científico de datos, y uno de los desafíos más comunes es lidiar con los valores faltantes. La presencia de NA (Not Available) en un conjunto de datos puede afectar los resultados de análisis y modelos, por lo que es crucial aplicar técnicas adecuadas para su tratamiento.
Una de las estrategias más efectivas es aprender a Eliminar NA en R, lo que permite depurar los datos y garantizar la calidad de los análisis. Existen diversas funciones y métodos en R que facilitan este proceso, permitiendo al usuario decidir cómo abordar los NA según las necesidades específicas de su análisis.
Métodos efectivos para eliminar NA en R
Uno de los métodos más comunes para eliminar NA en R es la función na.omit(). Este comando elimina cualquier fila que contenga al menos un valor NA en el conjunto de datos. Su uso es bastante sencillo y se puede aplicar directamente a data frames o vectores. Sin embargo, es importante considerar que este método puede reducir significativamente el tamaño del dataset, lo que puede afectar la representatividad de los datos.
Otra opción es utilizar la argumentación na.rm = TRUE en funciones como mean(), sum() o sd(). Este enfoque permite calcular estadísticas sin considerar los valores NA, manteniendo así la integridad de la estructura de datos original. La ventaja de esta técnica es que, en lugar de eliminar datos, simplemente se ignoran los NA en los cálculos, lo que puede ser útil en análisis exploratorios.
 Color CSS aleatorio
Color CSS aleatorioPara un control más granular sobre la eliminación de NA, se pueden emplear funciones del paquete dplyr, como filter(). Esta función permite aplicar condiciones específicas para filtrar datos, ofreciendo mayor flexibilidad en la gestión de NA. Por ejemplo, podrías querer conservar ciertas filas mientras eliminas otras en función de criterios específicos, lo que puede ser esencial para análisis más complejos.
Por último, es importante considerar el uso de tablas de comparación para evaluar el impacto de diferentes métodos de eliminación de NA. A continuación, se presenta una tabla que resume algunos de los métodos junto con sus características:
| Método | Descripción | Impacto en el Dataset |
|---|---|---|
na.omit() |
Elimina filas con NA | Reduce el tamaño del dataset |
na.rm = TRUE |
Ignora NA en cálculos | Preserva el tamaño del dataset |
dplyr::filter() |
Filtra basado en condiciones | Varía según criterios establecidos |
Cómo utilizar la función na.omit para limpiar datos en R
La función na.omit() se utiliza en R para eliminar de manera sencilla las filas que contienen valores NA en un conjunto de datos. Esta función es especialmente útil cuando se trabaja con data frames, ya que permite limpiar los datos de forma rápida y eficiente. Al aplicar na.omit, se asegura que los análisis posteriores no se vean afectados por la presencia de datos faltantes, lo que contribuye a obtener resultados más precisos.
Es importante tener en cuenta que, al utilizar na.omit(), se elimina cualquier fila que contenga al menos un valor NA. Esto puede conllevar a una reducción significativa del tamaño de tu dataset. Por ello, es recomendable evaluar el número de filas eliminadas antes de proceder. Puedes hacerlo utilizando funciones como nrow() para contar las filas originales y las filas después de aplicar na.omit().
Color CSS aleatorio comentarios YAML
comentarios YAMLEn caso de que necesites conservar ciertos datos mientras eliminas filas específicas, puedes combinar na.omit() con otras funciones de filtrado. Por ejemplo, podrías utilizar dplyr::filter() para establecer condiciones adicionales que te permitan decidir qué filas conservar en función de otros criterios. Esto proporciona un control más detallado sobre el proceso de limpieza de datos.
Finalmente, siempre es recomendable realizar un análisis exploratorio de datos antes y después de aplicar métodos como na.omit(). De esta manera, puedes visualizar el impacto de la eliminación de NA en tu conjunto de datos y asegurarte de que los resultados obtenidos sean fiables y representativos. Herramientas como gráficos de dispersión o tablas resumen pueden ser útiles en este paso para evaluar cómo eliminar NA en R afecta a tus análisis.
Estrategias para manejar valores faltantes en conjuntos de datos de R
El manejo de valores faltantes es una tarea esencial al trabajar con conjuntos de datos en R. Existen diversas estrategias que permiten abordar la problemática de los NA de manera efectiva. Entre ellas, se destacan:
- Eliminación completa: Usar funciones como
na.omit()para eliminar filas con NA. - Imputación: Reemplazar los NA con valores medios, medianas o mediante técnicas más complejas como KNN.
- Filtrado condicional: Utilizar
dplyr::filter()para conservar filas que cumplan con criterios específicos. - Estadísticas robustas: Aplicar
na.rm = TRUEen funciones para ignorar NA durante los cálculos.
La eliminación de NA en R puede ser simple, pero es crucial considerar su impacto en el análisis. Por ejemplo, al usar na.omit(), se eliminan todas las filas que contengan al menos un NA, lo que puede llevar a una reducción considerable en el tamaño del dataset. Por lo tanto, es recomendable realizar un análisis previo para determinar cuántas filas se eliminarán y cómo afectará esto a la representatividad de los datos. En este sentido, la función nrow() puede ser útil para conocer el número de filas antes y después de la aplicación de la función.
Color CSS aleatoriocomentarios YAML Cómo instalar Terminator en Ubuntu 22.04
Cómo instalar Terminator en Ubuntu 22.04Otra estrategia común es la imputación de valores, que consiste en reemplazar los NA con estimaciones. Esto puede llevarse a cabo de diferentes maneras, tales como:
- Reemplazar con la media o mediana de la columna.
- Usar métodos de regresión para estimar los valores perdidos.
- Implementar técnicas de aprendizaje automático como KNN para una imputación más sofisticada.
Al final, la selección de la estrategia adecuada dependerá del contexto del análisis y de la naturaleza de los datos. Es recomendable realizar un análisis exploratorio que incluya la visualización de los datos antes y después de aplicar métodos para eliminar o tratar los NA, asegurando así que los resultados obtenidos sean confiables y válidos para el análisis posterior.
Eliminar NA en R: Comparación entre diferentes métodos
Al abordar la cuestión de eliminar NA en R, es fundamental conocer las diversas opciones disponibles y cómo cada una puede impactar el análisis. Además de la función na.omit(), que elimina completamente las filas con NA, existen métodos alternativos como na.rm = TRUE que permiten realizar cálculos mientras se ignoran esos valores faltantes. Este enfoque es especialmente útil cuando se busca preservar el tamaño del dataset y mantener la representatividad de los datos originales.
Otro método interesante es el uso de la función filter() del paquete dplyr, que proporciona un control más granular sobre qué datos se eliminan. Esta función permite establecer condiciones específicas, lo que resulta ideal para contextos en los que solo ciertos NA deben ser tratados. Al emplear este método, se pueden conservar filas relevantes que, aunque contengan NA, aporten valor a los resultados finales del análisis.
Color CSS aleatoriocomentarios YAMLCómo instalar Terminator en Ubuntu 22.04 Cómo eliminar una cuenta de IONOS
Cómo eliminar una cuenta de IONOSSi el objetivo es entender mejor el impacto de la eliminación de NA, se puede implementar un enfoque mixto. Por ejemplo, se podrían utilizar gráficos o tablas que muestren la distribución de los datos antes y después de aplicar métodos como na.omit() o filter(). Esto no solo ayuda a visualizar cómo se ve afectado el dataset, sino que también permite una reflexión crítica sobre cómo se están manejando los datos faltantes. Comparar varias estrategias puede facilitar la toma de decisiones informada sobre cómo eliminar R y qué método es el más adecuado en cada situación.
En resumen, comprender las ventajas y desventajas de cada método para eliminar NA en R es esencial. Mientras que na.omit() es rápido y eficaz para una limpieza inicial, la combinación de enfoques como na.rm = TRUE y dplyr::filter() puede ofrecer mayor flexibilidad y precisión. Cada analista debe evaluar cuidadosamente su conjunto de datos y el contexto de su análisis para elegir la mejor estrategia en el manejo de NA.
Impacto de los valores NA en análisis de datos en R
La presencia de valores NA en un conjunto de datos puede tener un impacto significativo en el análisis en R. Estos valores faltantes pueden distorsionar resultados estadísticos, afectar modelos predictivos y alterar la interpretación de los datos. En consecuencia, es fundamental evaluar cómo los NA afectan las métricas, incluyendo medias, medianas y desvíos estándar, ya que su inclusión o exclusión puede llevar a conclusiones erróneas si no se manejan adecuadamente.
Un aspecto crítico es que los análisis que involucran NA pueden generar sesgos, especialmente en datos no aleatorios. Por ejemplo, si se utiliza na.omit() sin un análisis previo, se pueden perder patrones importantes en los datos, lo que impacta directamente en la calidad de las conclusiones. Para evitar esto, es recomendable utilizar funciones como na.rm = TRUE en cálculos estadísticos, que permiten ignorar los NA sin comprometer el tamaño del conjunto de datos, conservando así la representatividad de la muestra.
Además, los NA pueden afectar el rendimiento de algoritmos de aprendizaje automático, donde la presencia de datos incompletos puede llevar a modelos menos precisos. Por lo tanto, es esencial implementar una estrategia de eliminación o imputación adecuada. Utilizar paquetes como dplyr para aplicar filter() puede ofrecer un control más fino sobre qué datos se eliminan, permitiendo conservar información valiosa que de otro modo se descartaría al aplicar na.omit().
Finalmente, la forma en que se manejan los NA debe ser parte integral del análisis exploratorio de datos. Es recomendable realizar visualizaciones y resúmenes que reflejen el impacto de los NA, permitiendo así una comprensión más clara de cómo estos valores afectan el conjunto de datos. Evaluar métodos como na.rm = TRUE y compararlos con técnicas de eliminación puede proporcionar una perspectiva más completa sobre el manejo de datos faltantes y mejorar la calidad de los análisis realizados en R.
Consejos para optimizar la eliminación de NA en R
Para optimizar la eliminación de NA en R, es fundamental elegir el método adecuado según el contexto de los datos. Si decides usar na.omit(), asegúrate de evaluar cuántas filas se eliminarán y si esto afectará la representatividad de tu dataset. Una opción valiosa es combinar na.omit con el uso de nrow() para contar filas antes y después de la eliminación, lo que te permitirá tener un panorama claro del impacto en tus datos.
Adicionalmente, el uso de dplyr::filter() ofrece un enfoque más flexible y específico. Al establecer condiciones para filtrar los datos, puedes conservar filas que, aunque contengan NA, sean relevantes para tu análisis. Este método no solo te ayuda a eliminar NA de manera más controlada, sino que también maximiza el uso de la información disponible en tu dataset.
Otra estrategia útil es la imputación de valores, que puede ser más adecuada en ciertos casos. Considera reemplazar los NA con promedios, medianas o incluso usar técnicas avanzadas como KNN. Este enfoque puede mejorar la calidad de tu análisis al evitar la pérdida de datos valiosos, permitiendo que las estadísticas y modelos sean más representativos de la realidad.
Finalmente, no subestimes la importancia de realizar un análisis exploratorio antes y después de aplicar métodos para eliminar NA. Visualizar cómo los datos cambian con la eliminación de valores faltantes puede ofrecerte insights importantes y asegurarte de que tus conclusiones sean sólidas. Utiliza gráficos y tablas para comparar el estado de los datos antes y después de aplicar na.omit o dplyr::filter(), facilitando así una evaluación más profunda de tus resultados.
Deja una respuesta